Multi-View Region of Interest Prediction for Autonomous Driving Using Semi-Supervised Labeling
Sep 20, 2020· ,,,,·
0 min read
,,,,·
0 min read
Markus Hofbauer
Christopher Kuhn
Jiaming Meng
Goran Petrovic
Eckehard Steinbach
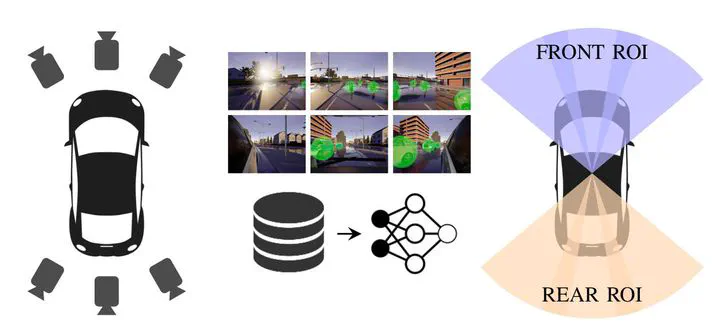 Image credit: IEEE
Image credit: IEEEAbstract
Visual environment perception is one of the key elements for autonomous and manual driving. Modern fully automated vehicles are equipped with a range of different sensors and capture the surroundings with multiple cameras. The ability to predict human driver’s attention is the basis for various autonomous driving functions. State-of-the-art attention prediction approaches use only a single front facing camera and rely on automatically generated training data. In this paper, we present a manually labeled multi-view region of interest dataset. We use our dataset to finetune a state-of-the-art region of interest prediction model for multiple camera views. Additionally, we show that using two separate models focusing on either front or rear view data improves the region of interest prediction. We further propose a semi-supervised annotation framework which uses the best performing finetuned models for generating pseudo labels to improve the efficiency of the labeling process. Our results show that existing region of interest prediction performs well on front view data, but finetuning improves the performance especially for rear view data. Our current dataset consists of about 16000 images and we plan to further increase the size of the dataset. The dataset and the source code of the proposed semi-supervised annotation framework will be made available on GitHub and can be used to generate custom region of interest data.
Type
Publication
In 23rd IEEE International Conference on Intelligent Transportation Systems