Pixel-Wise Failure Prediction for Semantic Video Segmentation
Sep 19, 2021· ,,,·
0 min read
,,,·
0 min read
Christopher Kuhn
Markus Hofbauer
Ziqin Xu
Goran Petrovic
Eckehard Steinbach
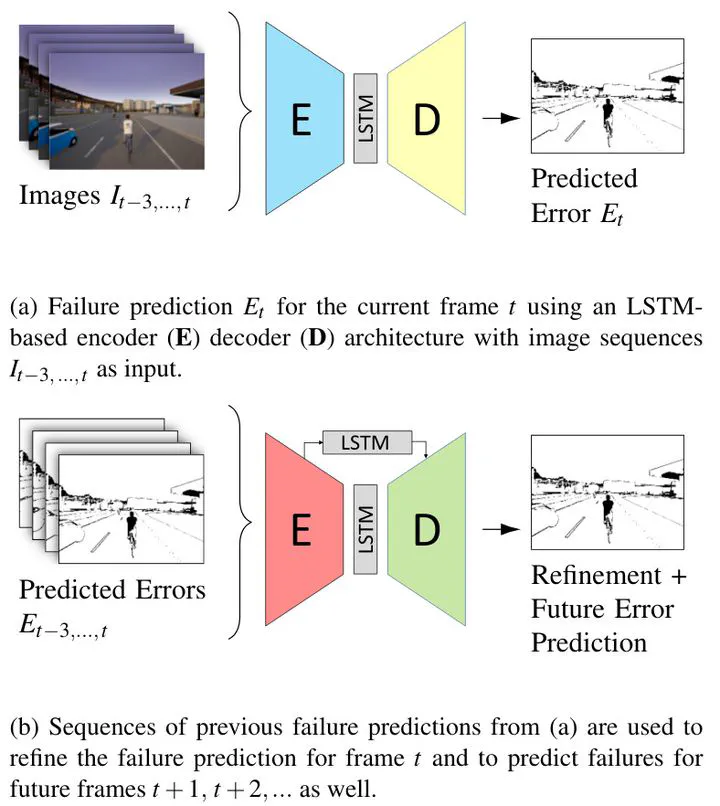 Image credit: IEEE
Image credit: IEEEAbstract
We propose a pixel-accurate failure prediction approach for semantic video segmentation. The proposed scheme improves previously proposed failure prediction methods which so far disregarded the temporal information in videos. Our approach consists of two main steps: First, we train an LSTM-based model to detect spatio-temporal patterns that indicate pixel-wise misclassifications in the current video frame. Second, we use sequences of failure predictions to train a denoising autoencoder that both refines the current failure prediction and predicts future misclassifications. Since public data sets for this scenario are limited, we introduce the large-scale densely annotated video driving (DAVID) data set generated using the CARLA simulator. We evaluate our approach on the real-world Cityscapes data set and the simulator-based DAVID data set. Our experimental results show that spatio-temporal failure prediction outperforms single-image failure prediction by up to 8.8%. Refining the prediction using a sequence of previous failure predictions further improves the performance by a significant 15.2% and allows to accurately predict misclassifications for future frames. While we focus our study on driving videos, the proposed approach is general and can be easily used in other scenarios as well.
Type
Publication
In 28th IEEE International Conference on Image Processing