Introspective Failure Prediction for Semantic Image Segmentation
Sep 20, 2020· ,,,·
0 min read
,,,·
0 min read
Christopher Kuhn
Markus Hofbauer
Sungkyu Lee
Goran Petrovic
Eckehard Steinbach
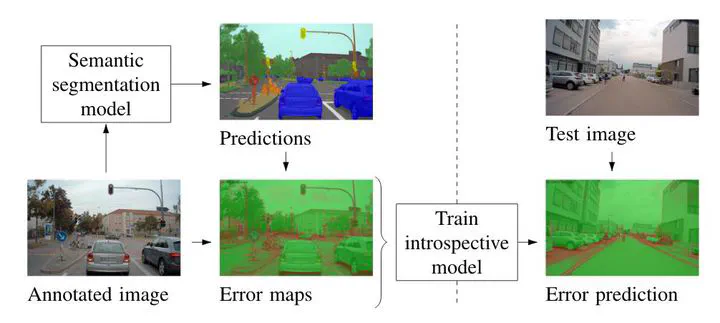 Image credit: IEEE
Image credit: IEEEAbstract
Semantic segmentation of images enables pixel-wise scene understanding which in turn is a critical component for tasks such as autonomous driving. While recent implementations of semantic image segmentation have achieved remarkable accuracy, misclassifications remain inevitable. For safety-critical tasks such as free-space computing, it is desirable to know when and where the segmentation will fail. We propose using the concept of introspection to predict the failures of a given semantic segmentation model. A separate introspective model is trained to predict the errors of a given model. This is accomplished by training the given model with the errors made on a set of previous inputs. By using the same architecture for the introspective model as for the semantic segmentation, the proposed model learns to predict pixel-wise failure probabilities. This allows to predict both when and where the semantic segmentation will fail. Sharing the feature encoder with the inspected model reduces training and inference time while improving performance. We evaluate our approach on the large-scale A2D2 driving data set. In a precision-recall analysis, the proposed method outperforms two state-of-the-art uncertainty estimation methods by 3.2% and 6.7% while requiring significantly less resources during inference. Additionally, combining introspection with a state-of-the-art method further increases the performance by up to 3.7%.
Type
Publication
In 23rd IEEE International Conference on Intelligent Transportation Systems