Adaptive Live Video Streaming for Teleoperated Driving
Failures of autonomous vehicles are inevitable. One possible solution to cope with foreseeable failures is teleoperation. In teleoperated driving, a human operator controls the vehicle from a distance. The remote operator perceives the traffic situation via video streams from one or more cameras deployed in the vehicle. The control commands of the operator are transmitted to the vehicle. To resolve complex traffic situations and ensure safety, the operator requires a reliable low delay video transmission. This is particularly relevant for mobile networks with time-variant and limited transmission rates. To provide the remote operator with the best possible situation awareness, while matching the available transmission resources of the network, an adaptation scheme for the individual video streams is required.
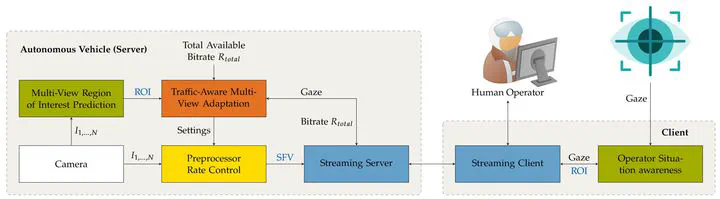
In this thesis, we investigate adaptive video streaming for teleoperated driving. We consider the entire pipeline of a general teleoperated driving system and we propose four main additions: an in-lab teledriving system and streaming pipeline, a driver situation awareness assessment system, a traffic-aware multi-view adaptation scheme, and a preprocessor rate control approach designed for the resource-constrained encoding hardware of autonomous vehicles.
To evaluate all proposed methods in a controllable network and driving environment, we design a teleoperation framework that extends existing driving simulators by vehicle remote control. This framework includes a customizable user interface as well as a low delay video streaming pipeline. The streaming pipeline provides an adaptation interface for controlling the frame rate, frame size, bitrate, and quality of the video stream.
While a framework with low delay video streaming can provide the driver with the necessary visual information to understand the current situation, there is no guarantee that the driver actually recognizes all relevant elements correctly. As the second main contribution, we therefore propose a method for assessing the driver situation awareness in realtime. The driver’s current situation awareness is measured using eye tracking and compared to the optimal situation awareness. The optimal situation awareness is estimated by a state-of-the-art region of interest prediction network, which we extended for multiple camera views. The proposed driver awareness model enables us to accurately measure the driver situation awareness, which has been validated in a user study for eight driving scenarios.
Next, we propose a traffic-aware multi-view adaptation scheme to provide the operator with the best possible situation awareness for the current traffic situation. The adaptation scheme first estimates the importance of each camera view based on the vehicle’s realtime movement in traffic. Then, the optimal combination of frame rate, frame size, and target rate/quality is estimated using a quality-of-experience-driven multi-dimensional adaptation scheme to control the encoder of each individual video stream. Evaluated for three representative driving scenarios with a six camera setup, the proposed adaptation scheme increases the average video quality per camera by 5 % VMAF score compared to a uniform adaptation.
Finally, the hardware of autonomous vehicles is limited by size and cost. The vehicle is therefore often restricted to a single hardware encoder. Encoding all camera views at the same time with a single encoder requires the combination of the individual frames into a single superframe. While this is a possible solution for streaming multiple camera views, it prevents the adaptation of the individual camera views. In this thesis, we propose a preprocessing concept that allows for individual rate/quality adaptation while using a single encoder. The preprocessing filters control the frame rate, frame size, and target rate/quality of the individual frames before combining them into a single superframe. For three representative driving scenarios, the proposed approach achieves the same video quality for the most important views as when using multiple encoders, while it causes only 1.8 % quality reduction on the remaining views. In comparison, an approach using a single encoder without preprocessing causes quality degradations of 4.5 % for the remaining views and even 5.6 % on the most important views.