Evaluation of Video Coding for Machines without Ground Truth
May 22, 2022· ,,,·
0 min read
,,,·
0 min read
Kristian Fischer
Markus Hofbauer
Christopher Kuhn
Eckehard Steinbach
Andre Kaup
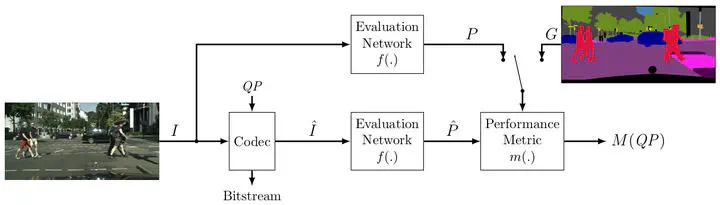 Image credit: IEEE
Image credit: IEEEAbstract
In the emerging field of video coding for machines, video datasets with pristine video quality and high-quality annotations are required for a comprehensive evaluation. However, existing video datasets with detailed annotations are severely limited in size and video quality. Thus, current methods have to either evaluate their codecs on still images or on already compressed data. To mitigate this problem, we propose an evaluation method based on pseudo ground-truth data from the field of semantic segmentation to the evaluation of video coding for machines. Through extensive evaluation, this paper shows that the proposed ground-truth-agnostic evaluation method results in an acceptable absolute measurement error below 0.7 percentage points on the Bjøntegaard Delta Rate compared to using the true ground truth for mid-range bitrates. We evaluate on the three tasks of semantic segmentation, instance segmentation, and object detection. Lastly, we utilize the ground-truth-agnostic method to measure the coding performances of the VVC compared against HEVC on the Cityscapes sequences. This reveals that the coding position has a significant influence on the task performance.
Type
Publication
In 2022 IEEE International Conference on Acoustics, Speech and Signal Processing