Better Look Twice - Improving Visual Scene Perception Using a Two-Stage Approach
Dec 2, 2020· ,,·
0 min read
,,·
0 min read
Christopher Kuhn
Markus Hofbauer
Goran Petrovic
Eckehard Steinbach
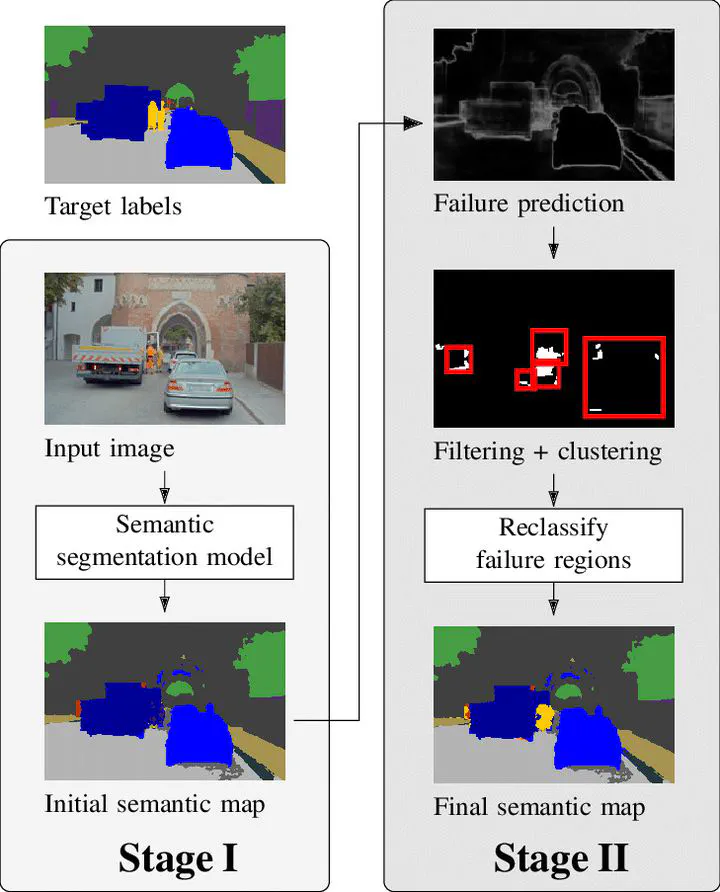 Image credit: IEEE
Image credit: IEEEAbstract
Accurate visual scene perception plays an important role in fields such as medical imaging or autonomous driving. Recent advances in computer vision allow for accurate image classification, object detection and even pixel-wise semantic segmentation. Human vision has repeatedly been used as an inspiration for developing new machine vision approaches. In this work, we propose to adapt the “zoom lens model” from psychology for semantic scene segmentation. According to this model, humans first distribute their attention evenly across the entire field of view at low processing power. Then, they follow visual cues to look at a few smaller areas with increased attention. By looking twice, it is possible to refine the initial scene understanding without requiring additional input. We propose to perform semantic segmentation the same way. To obtain visual cues for deciding where to look twice, we use a failure region prediction approach based on a state-of-the-art failure prediction method. Then, the second, focused look is performed by a dedicated classifier that reclassifies the most challenging patches. Finally, pixels predicted to be errors are updated in the original semantic prediction. While focusing only on areas with the highest predicted failure probability, we achieve a classification accuracy of over 63% for the predicted failure regions. After updating the initial semantic prediction of 4000 test images from a large-scale driving data set, we reduce the absolute pixel-wise error of 232 road participants by 10% or more.
Type
Publication
In 22nd IEEE International Symposium on Multimedia